Today I Learned the Cholesky Decomposition
Cholesky decomposition
Not long ago I picked up a Matrix Analysis textbook and came across a matrix factorization with this entry's namesake. The Cholesky decomposition factorizes a positive-definite matrix ; for all non-zero into a product of a lower triangular matrix and its adjoint:
For a positive-definite matrices such a factorization always exists and is unique. The numerical algorithm for constructing the lower triangular matrix is relatively straightforward. Initially, the matrix begins as a zero matrix with appropriate dimensions. Taking the diagonal elements of () and arranging them in a non-increasing order, the algorithm proceeds as follows:
- At step , update the diagonal elements of with those of , .
- Update the , for .
- Update the stored diagonal elements of , for
- Increment and go back to step 1 and repeat until is equal to index of the last row of the matrix .
A Python implementation of this algorithm can fit in a tweet
import numpy as np
def cholesky(A):
m, _ = A.shape
for i in range(m):
A[i,i] = np.sqrt(A[i,i])
A[i+1:, i] /= A[i, i]
A[i, i+1:] = 0
A[i+1:, i+1:] = np.outer(A[i+1:, i], A[i+1:,i])The above algorithm can be slightly modified to obtain a low rank approximation of , by stopping when all the remaining updated diagonal elements are below some specified tolerance . For some instances of , e.g. electron repulsion integrals in quantum chemistry, the rank of the resulting matrix can be much smaller than its maximum possible value.
Here's an animated GIF of what the algorithm does for a positive-definite matrix:
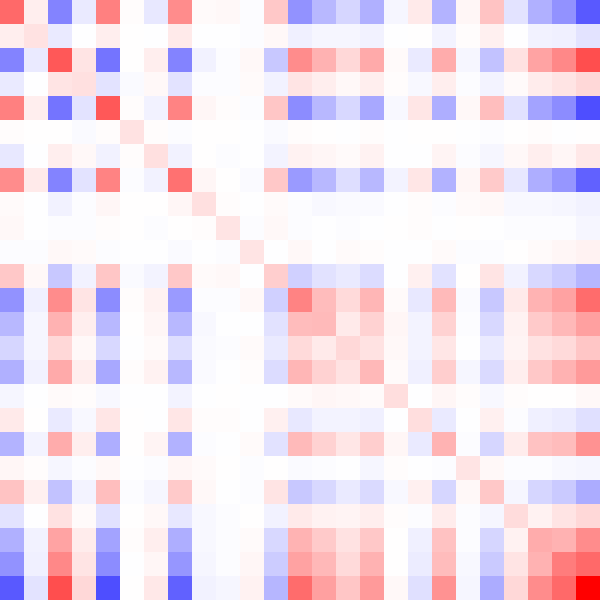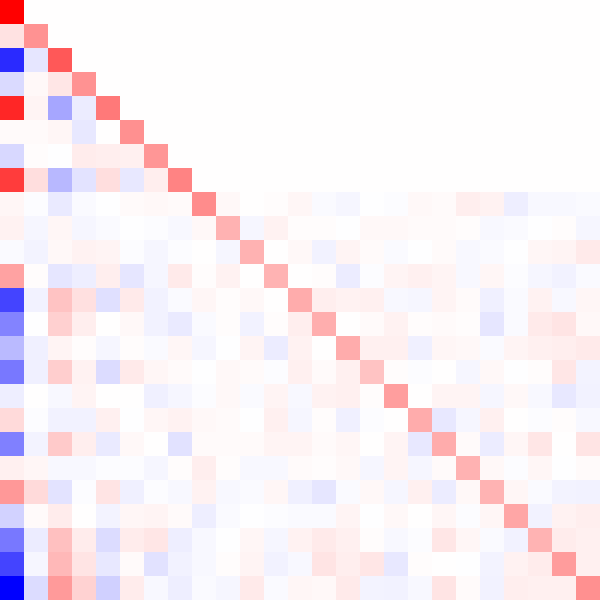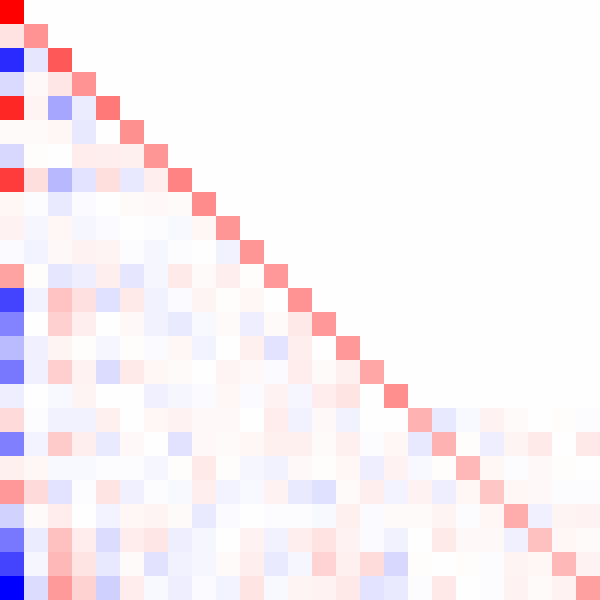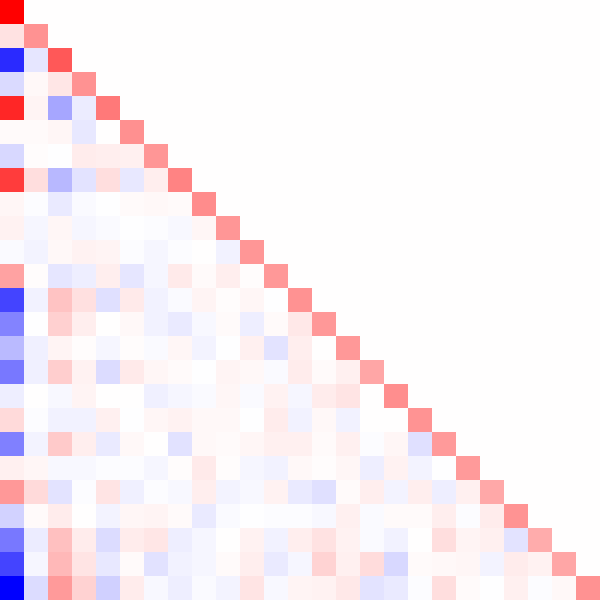
Fin.